Time series forecasting is extensively used in numerous practical fields such as business, economics, finance, science and engineering. The main aim of a time series analysis is to forecast future values of a variable using its past values.

In this post, I will give you a detailed introduction to time series modelling. This would be the first of a two part blog post series.
Edit – You can find the second part here – Understanding Time Series Modelling and Forecasting, Part 2
Table of Contents
- Basic Statistics for time series
- Trend and Seasonality
- Stationary Time Series
- Autoregressive (AR) Models
- Moving Average (MA) Models
- Autocorrelation Function (ACF)
- Partial Autocorrelation Function (PACF)
- Autoregressive Moving Average (ARMA) models
- Differencing in time series
- ARIMA models (Introduction)
I will only cover the univariate time series. A univariate time series is a sequence of measurements of the same variable collected over time. Most often, the measurements are made at regular intervals.
Lets talk some statistics
Before diving into time series analysis I want to briefly skim over some relevant terms in statistics that you will find useful while going through this post. Please feel free to skip this section if you are comfortable with the terms mentioned.
Random Variable – These are not the traditional variables that you were first exposed to in your algebra class. They are outcomes of a random process. For example, the number of visitors of a restaurant on a particular day.
Expected Value – The expected value is the probability-weighted-average of a random variable. Intuitively, it is the average value of the outcomes of the experiment it represents. For example, the expected value of a dice throw is 3.5.
Variance – The measure of spread of the probability distribution of a random variable. It determines the degree to which the values of a random variable differ from the expected value. The square root of variance is standard deviation.
Var(X) =E[(X – E[X])2], where X is a random variable and E[X] is its expectation.
Covariance – The measure of the joint variability of two random variables. It depends on the magnitude of the variables.
Cov(X, Y) = E[ (X – E[X]) (Y – E[Y]) ], where X and Y are random variables.
Autocovariance – The covariance of a random variable with itself at different points of time. For example, Cov(Xt , Xt-h) . Please note that here, Xt and Xt-h are also random variables.
Correlation – It is the scaled form of covariance. It is dimensionless.
Corr(X, Y) = Cov(X, Y) / (sd(X) * sd(Y) ),
where sd(X) is the square root of variance (standard deviation) of X.
Autocorrelation – Similar to autocovariance, it is the correlation of a random variable with itself at different points of time. For example, Corr(Xt , Xt-h)
White Noise – A collection of uncorrelated random variables, with mean 0 and a finite variance.
If you want to get a more detailed explanation of these terms, I would recommend the excellent tutorial series on statistics by Khan Academy.
Time Series Components
Trend and seasonality are two common components of a time series. I feel I should discuss this beforehand to avoid any confusion later.
Trend – The tendency of the measurements to increase or decrease on average with time. For example, the cost of a Big Mac, often taken as a measure of inflation has had an increasing trend over the years.
Seasonality – Repeating pattern of highs and lows as we move along time. For example, the sale of Christmas trees by month.
Lets look at some time series plots to get a basic understanding of these components.
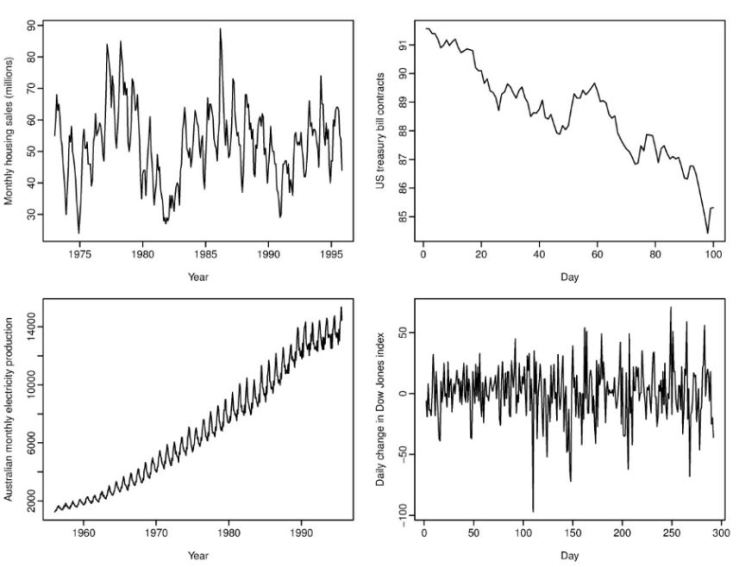
- The top left plot shows, the monthly housing sales within each year. It has strong seasonality but no trend.
- The top right plot shows the US treasury bill contracts from the Chicago market for 100 consecutive trading days in 1981. This shows a strong downward trend but no seasonality.
- The bottom left plot displays the Australian monthly electricity production . It has strong seasonality as well as strong trend.
- The bottom right plot depicts the change in the Dow Jones Index on a daily basis. This data has no seasonality and no trend.
The above plots can be reproduced by the following R code –
if(!require("fpp")) install.packages("fpp") par(mfrow=c(2, 2)) plot(hsales, xlab="Year", ylab="Monthly Housing Sales (millions)") plot(ustreas, xlab="Day", ylab="US Treasury Bill Contracts") plot(elec, xlab="Year", ylab="Australian Monthly Electricity Production") plot(diff(dj), xlab="Day", ylab="Daily Change in Dow Jones Index")
Stationary Time Series
A stationary time series is a very important concept in understanding time series modelling. All the modelling techniques discussed are based on the assumption that our time series is weakly stationary. In case, we encounter a non-stationary series we will first convert it into a weakly stationary series and then proceed with modelling.
A series xt is said to be a weakly stationary series if it satisfies the following properties –
- The mean, E(xt) is same for all t.
- Variance of xt is same for all t.
- The covariance and correlation between xt and xt-h depends only on the lag, h. Hence, the covariance and correlation between xt and xt-h is same for all t.
From now on, whenever I mention a stationary series, it would mean that I am talking about a weakly stationary series.
Some examples of non-stationary series –
- a series with a continual upward trend.
- a series with a distinct seasonal pattern.
Now, lets talk about some of the modelling techniques in time series analysis that are used in forecasting. We will start with modelling stationary and non-seasonal series. After this we will see, how to deal with non-stationary and seasonal data.
Autoregressive (AR) Models
An autoregressive (AR) model assumes that the present value of a time series variable can be explained as a function of its past values.
xt = φ1xt-1 + φ2xt-2 + ……………….. + φpxt-p + wt
where, wt is the error term and xt is stationary.
An AR model is said to be of order p if it is dependent on p past values and is denoted as AR(p).
An important thing to note about AR models is that they are not the same as the standard linear regression models because the data in this case is not necessarily independent and not necessarily identically distributed.
INTUITION
Lets discuss a practical example to get a feel about the kind of information an AR model incorporates.
Consider, the number of blankets sold in a city. On a particular day, the temperature dropped below normal and there was an increase in the sale of blankets (xt-1). The next day, the temperature went back to normal but there was still a significant demand of blankets (xt). This could be due to the fact that the number of blankets sold depends on the current temperature but it is also affected by the past sale of blankets. This situation can be expressed as –
xt = φ1xt-1 + wt
Moving Average (MA) Models
In moving average (MA) models, the present value of a time series is explained as a linear representation of the past error terms.
xt = θ1wt-1 + θ2wt-2 + ……………….. + θqwt-q + wt
where wk is the error at time k, xt is stationary and mean of the series is 0.
An MA model is said to be of order q if it is dependent on q past error terms and is denoted as MA(q).
INTUITION
Consider a car manufacturer who manufactured 10000 special edition cars. This edition was a success and he managed to sell all of them (lets call this xt-1). But there were some 1500 customers who could not purchase this car as it went out of stock (lets call this as wt-1). Some of these 1500 customers settled buying some other car but some returned the next month when this special edition car was back in stock. Mathematically, the above scenario can be depicted as,
xt = θ1wt-1 + wt
It is usually difficult to guess a suitable model by just looking at the data. We need certain techniques to come up with a suitable forecasting model. Understanding the autocorrelation function and the partial autocorrelation function is an important step in time series modelling.
Autocorrelation Function (ACF)
As discussed earlier, for a stationary series the autocorrelation between xt and xt-h depends only on the difference (lag) of the two measurements.
Therefore, for a time series the autocorrelation function is a function of lag, h. It gives the correlation between two time dependent random variables with a separation of h time frames.
ACF plots are used to infer the type and the order of the models that can be suitable for a particular forecasting problem.
Autocorrelation Function of an AR(p) model
The autocorrelation function of an AR model dampens exponentially as h increases. At times, the exponential decay can also be sinusoidal in nature.

In practice, a sample won’t usually provide such a clear pattern. But such an exponential decay is usually indicative of an AR model. But ACF plots cannot tell you the order of the AR model. To determine the order, we use the partial autocorrelation function plot, but more on that later.
Autocorrelation of an MA(q) model
The autocorrelation function of an MA(q) model cuts off at lag q. It means that it will have a finite value for lags, h ≤ q.
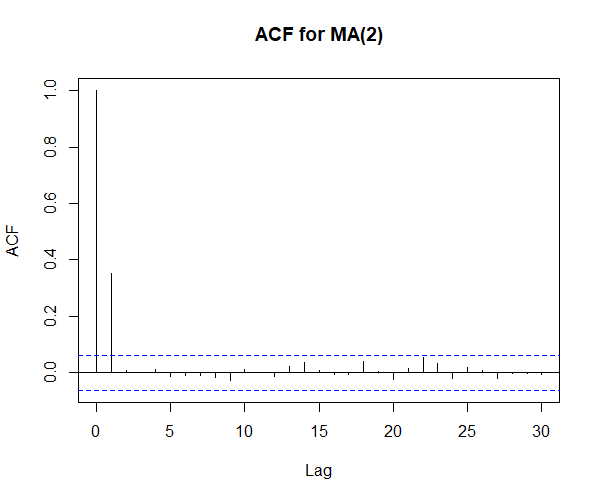
If the ACF plot has such a characteristic, we can decipher the order of the MA model as well. Again, in practice, a sample won’t usually provide such a clear pattern. But a resemblance to such a plot would suggest an MA model.
Partial Autocorrelation Function (PACF)
We can understand the order of an MA(q) model by looking at its ACF plot. But this is not feasible with an AR(p) model. Hence, we use the partial autocorrelation function for this. It is the correlation between xt and xs with the linear effect of everything in the middle removed.
Let us consider an AR(1) model, xt = φ1xt-1 + wt . We know, that the correlation between xt and xt-2 is not zero , because xt is dependent on xt-2 through xt-1 . But what if we break this chain of dependence by removing the effect of xt-1. That is, we consider the correlation between xt − φxt-1 and xt-2 − φxt-1 , because it is the correlation between xt and xt-2 with the linear dependence of each on xt-1 removed. In this way, we
have broken the dependence chain between xt and xt-2. Hence,
cov(xt − φxt-1, xt-2 − φxt-1) = cov(wt, xt-2 − φxt − 1) = 0
PACF of an AR(p) model
The PACF for an AR(p) model cuts off after p lags.
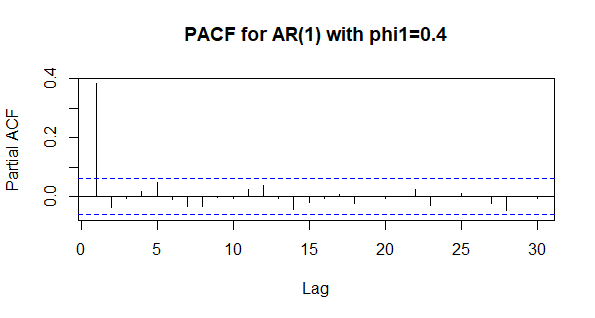
PACF of an MA(q) model
Similar to the ACF of an AR(p) model, the PACF of an MA(q) model tails off as the lag increases.

I will not derive the mathematical expressions for the ACF and PACF plots. But, using the assumptions of a stationary series, the AR and MA equations and the definition of autocorrelation it can be easily accomplished.
What are these horizontal blue lines in the ACF and PACF plots?
For those who are not comfortable with inferential statistics – We always work with sample data. We cannot find out true population parameters. Therefore, we find out sample statistics (in this case the sample autocorrelation) to estimate the true population parameter (or, the true autocorrelation). The blue lines denote the confidence interval of our estimate. If the autocorrelation value in the plot is inside the blue lines we assume it to be zero (statistically insignificant). You would not have to worry about calculating the confidence intervals as most of the software packages you use would do it for you.
For those who are comfortable with inferential statistics – We take,
null hypothesis: autocorrelation for a particular lag, ρ(h) = 0
alternate hypothesis: ρ(h) ≠ 0
The blue lines represent the ±2 standard errors region. We reject the null hypothesis if our sample estimate is outside this boundary.
Autoregressive Moving Average (ARMA) Models
Most often using only AR or MA models does not give the best results. Hence, we use ARMA models. These models incorporate the autoregressive as well as the moving average terms. An ARMA model can be represented as,
xt = φ1xt-1 + φ2xt-2 + ….. + φpxt-p + θ1wt-1 + θ2wt-2 + ….. + θqwt-q + wt
An ARMA model dependent on p past values and q past error terms are denoted as ARMA(p,q).
Behavior of the ACF and PACF for ARMA Models –
| AR(p) | MA(q) | ARMA(p,q) | |
|
ACF |
Tails Off |
Cuts off after lag q |
Tails Off |
| PACF | Cuts off after lag p | Tails Off |
Tails Off |
Differencing
Till now we have only talked about stationary series. But what if we encounter a non-stationary series? Well, as I mentioned earlier, we will have to come with strategies to stationarize our time series.
Differencing is one such and perhaps the most common strategy to stationarize non-stationary series. Consider,
xt = μ + φxt-1 + wt ………… (1)
xt-1 = μ + φxt-2 + wt-1 ………… (2)
Subtracting (2) from (1) we get,
xt-1 – xt= φ(xt-2 – xt-1) + wt-1 – wt
Here, we removed a linear trend in the data by doing a first order differencing. After fitting a model on the differenced terms, we can always retrieve the actual terms to get their forecasted values.
Example of a second order differencing,
(xt – xt-1) – (xt-1 – xt-2)
Autoregressive Integrated Moving Average (ARIMA) Models
They are nothing but ARMA models applied after differencing a time series. In most of the software packages, the elements in the model are specified in the order –
(AR order, differencing order, MA order)
For example,
- MA(2) => ARIMA(0, 0, 2)
- ARMA(1,3) => ARIMA(1, 0, 3)
- AR(1), differencing(1), MA(2) => ARIMA(1, 1, 2)
I will discuss ARIMA models in detail in my second blog post on time series which would involve forecasting and diagnostic steps in ARIMA modeling, seasonal ARIMA models and ARIMA modeling in R.
Edit – You can find the second part here – Understanding Time Series Modelling and Forecasting, Part 2
Further Reading
- A complete tutorial on Time Series Modelling in R by Analytics Vidhya
- Stat 510 Applied Time Series Analysis – Online Course by University of Pennsylvania
- Introduction to Time Series Analysis by Datacamp
Please stay tuned. I will soon be out with the second part of this post.
If you liked this you might also be interested in some of my other posts –
- Who was the lead character in Friends? The Data Science Answer
- How to one hot encode categorical variables of a large dataset in Python?
Thanks a lot. 🙂

[…] As promised, this is the second post on my two part blog series on time series modelling and forecasting. In my first blog post I discussed the basics of time series analysis and gave a theoretical overview. In case you missed it you can find it here – Understanding Time Series Modelling and Forecasting, Part 1 […]
LikeLike
Very nice article. Thanks!
LikeLike
Really enjoyed it. Thanks
LikeLike