Neural Machine Translation has arguably reached human-level performance. But, effective training of these systems is strongly dependent on the availability of a large amount of parallel text. Because of which supervised techniques have not been so successful in low resource language pairs. Unsupervised Machine Translation requires only monolingual corpora and is a viable alternative in such cases. While it has not been able to outperform supervised learning with lots of parallel resources, it has great potential with low resource language pairs.
The working of supervised MT systems makes intuitive sense. The input is a source sentence and the output is its translation in the target sentence. But unsupervised MT is at times difficult to grasp especially when they leverage only monolingual corpora of source and target languages. In an attempt to explain the general working of such systems, I will discuss an unsupervised machine translation method that was presented at ICLR 2018.
This model comes from a paper published by Facebook AI Research – Unsupervised Machine Translation Using Monolingual Corpora Only. They propose a method in which the model leverages only monolingual corpora in two different languages and maps sentences from both the languages in a common feature space. From this common feature space, the model is forced to reconstruct sentences in both languages. Let’s call this common feature space latent space from now on.
Before going through the overall working of the model, let’s go through the individual components. The translation model comprises an encoder, a decoder, pre-trained embeddings for both the languages and a discriminator.
Pre-Trained Embeddings
The embeddings for the source and the target language are trained on the two monolingual corpora separately using FastText. Then, a bilingual dictionary is learned using an unsupervised method (Word Translation Without Parallel Data). This can be used for word-by-word translation. Using this procedure, we now have a common set of embeddings for words from both the languages.
Encoder
Given an input sequence of n words in a particular language (source or target), the encoder (a bidirectional-LSTM) computes a sequence of n hidden states by using the pre-trained word embeddings. These hidden states are vectors in the latent space we mentioned earlier. It is important to note that the encoder does not differentiate between the two languages and has a shared set of LSTM layer weights for both. This means that the input sequence of words (in the form of embeddings) can be from any of the two languages and the same encoder converts them into vectors of the latent space.
Decoder
The decoder (also an LSTM) takes as input the sequence of hidden vectors generated by the encoder and outputs a sequence of words in the target language. At each step, the decoder, takes as input the previous hidden state, the current word and a context vector given by a weighted sum over the encoder states. The process is repeated until the decoder generates a stop symbol indicating the end of the sequence.
Similar to the encoder, the decoder also has the same LSTM layer weights for both the languages. The input to the decoder includes a language-specific start symbol to make it generate output in a particular language. The encoder-decoder forms a sequence to sequence model with attention.
Discriminator
The discriminator is a neural network that is trained to classify the hidden vectors (of the latent space) generated by the encoder. The discriminator predicts whether a vector of the latent space is an encoding of a source sentence or a target sentence. It is used to accomplish a particular thing (more on this later).
Now that we have gone through the internal components of the model, let’s see the methods involved in training the full model. There are three steps taking place during model training –
- Denoising Auto-Encoding – The model learns to reconstruct a sentence in a given language from a noisy version of it.
- Cross-Domain Training – The model also learns to reconstruct any source sentence given a noisy translation of the same sentence in the target language, and vice versa.
- Adversarial training – The model is constrained to have the same distribution of the source and target latent vectors.
Denoising Auto-Encoding
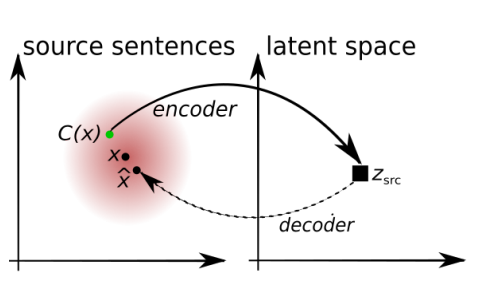
In this step, the system is trained to re-create its own input. It takes an input sentence, encodes it, and tries to reconstruct the original sentence in the same language. Since we have a common latent space, this would help in making the encoder and decoder learn how to convert the vectors of the latent space into the source or target sentences.
But, there is a problem with this training procedure. The model is just trying to learn a trivial copying task. Because of which, it may just learn to blindly copy input words in the output, without learning any real knowledge of the languages involved. To counter this, the authors propose the introduction of random noise in the input (similar to stacked denoising autoencoders). They randomly drop a word in the input sentence with some probability and shuffle the input sentence slightly. The system is then asked to reconstruct the original sentence from this noisy version.
The loss minimized in this step can be given as –
Lauto(θenc, θdec, Z, l) = E[Δ(x, x̂)]
where θenc is the encoder parameters, θdec is the decoder parameters, Z is the pre-trained embeddings, l is the source or target language, Δ is a measure of discrepancy (sum of token-level cross-entropy losses), x̂ is the reconstructed output of the model (x̂ ∼ decoder(encoder(noise(x), l), l)). The total loss for this step is,
Lauto(θenc, θdec, Z, l1) + Lauto(θenc, θdec, Z, l2)
Cross Domain Training
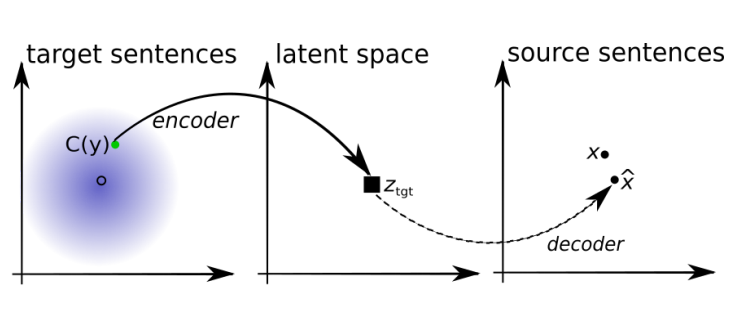
In this step, the system learns to translate the input sentence from one language into the other. The translation model (M) improves in an iterative procedure. We start with an initial model that is a naive word to word translation model from a dictionary learned in an unsupervised way. Let’s call this initial model Mi.
Now, a sentence is sampled from the source language. It is translated using Mi into the target language.
translated target sentence = Mi(source sentence)
The encoder-decoder system now tries to reconstruct a noisy version of this translated sentence back into the source language sentence by optimizing the following loss function –
Lcd(θenc, θdec, Z, l1, l2) = E[Δ(x̂, x)]
where θenc is the encoder parameters, θdec is the decoder parameters, Z is the pre-trained embeddings, l1 is the source language, l2 is the target language, Δ is again the sum of token-level cross-entropy losses, x̂ is the reconstructed output of the model (x̂ ∼ decoder(encoder(noise(translated target sentence), target), source)), and x is the initial source sentence.
The above step is done with both the languages being source and target alternately. The total loss for this step becomes –
Lcd(θenc, θdec, Z, l1, l2) + Lcd(θenc, θdec, Z, l2, l1)
After this, the current translation model is updated with the current encoder-decoder pair to get Mi+1. This process is iteratively repeated improving the encoder-decoder translation system on every step. At inference time, the final encoder-decoder system is directly used for translation.
Intuition: The idea behind the algorithm is that as long as the initial model retains at least some information of the input sentence, the encoder will map such translation to vectors in the latent space that also correspond to a cleaner version of the input because the encoder is trained to denoise. At the same time, the decoder is trained to predict noiseless outputs, given noisy features. Putting these two things together will produce less noisy translations, which will enable better back-translations at the next iteration, and so on so forth.
Adversarial Training
Since we have a shared space of encoded hidden vectors (the latent space) for both the languages, it is important for vectors encoded from the two languages to be not very different from one another (to have same distribution). Otherwise, the decoder will face problems during translation steps. To add such a constraint to the system, a discriminator (discussed earlier) is trained. It predicts the language (source or target) from which a latent space vector has been encoded. The encoder, on the other hand, is trained to fool the discriminator by optimizing –
Ladv(θenc, Z | θdiscrimiator) = -Log(Prob(L1 | encoder(x, L2)))
where θenc is the encoder parameters, Z is the pre-trained embeddings, θdiscrimiator is the discriminator parameters, x is the source sentence.
The discriminator loss is minimized in parallel to update the discriminator.
Final Objective

The final objective function at each step can be given as –
λauto [Lauto(θenc, θdec, Z, l1) + Lauto(θenc, θdec, Z, l2)]+
λcd [Lcd(θenc, θdec, Z, l1, l2) + Lcd(θenc, θdec, Z, l2, l1)] +
λadv [Ladv(θenc, Z | θdiscrimiator)]
where λauto, λcd, and λadv are hyper-parameters weighting the importance of the auto-encoding, cross-domain and adversarial loss.
Algorithm

Unsupervised Model Selection Criterion
Since there is no parallel data to measure the quality of the translation system, the authors adopt a proxy method of evaluation. All sentences in one language are translated into the other language and then translated back to the original language. The quality of the model is then evaluated by computing the BLEU score over the original inputs and their reconstructions via this two-step translation process. The performance is then averaged over the two directions, and the selected model is the one with the highest average score.
Similar Approaches
I only discussed a particular method for unsupervised translation. But the auto-encoding followed by back translation approach has been used in various other places. Unsupervised Neural Machine Translation is another paper presented at ICLR 2018 that leverages only monolingual corpora. Instead of having a shared encoder and decoder, this system only shares the encoder and has separate decoders for the two languages.

A more recent work – Phrase-Based & Neural Unsupervised Machine Translation has also been published by Facebook AI Research in which the authors highlight three key requirements for unsupervised MT – a good initialization, language modeling, and modeling the inverse task (via back-translation).
Conclusion
While still not able to complete with supervised learning having a large amount of parallel data, unsupervised MT has a lot of promise for low resource languages. I hope there is more work on similar unsupervised methods in the future. Thank You 🙂

I searched lot of blog but cant find any information about the part of machine learning that is unsupervised learning and is the most important part of machine learning.. thanks for sharing it….
LikeLiked by 1 person
Hi @Yashu Seth, thanks for this article. Quite easy to understand and follow.
My Question: Do you have have an idea if it is possible to use the ‘Denoising Auto-Encoding’ separately during test time? I mean can I give the model a wrong sentence and it gives me a correct sentence at test time (while it is also be able to do right translation also)?
LikeLike
Hello,
This is really an informative article.
Thanks for sharing this useful post.
LikeLike
excellent post
LikeLike