
Question answering is a very popular natural language understanding task. It has applications in a wide variety of fields such as dialog interfaces, chatbots, and various information retrieval systems. Answering questions using knowledge graphs adds a new dimension to these fields.
“Question answering over knowledge graphs (KGQA) aims to provide the users with an interface to ask questions in natural language, using their own terminology, to which they receive a concise answer generated by querying the KG.” (Source)
In this blog post, I introduce the KGQA (knowledge graph question answering) task and discuss various methods involved in it. But first, let’s go through a brief description of knowledge graphs.
What is a Knowledge Graph?
A knowledge graph is a graph-based data model that describes real-world entities and relations between them. For example, “Gal Gadot” and “Israel” are entities and “born_in” is the relation between them. An entity can also be linked to a data value, often referred to as literals, e.g., “30 April 1985”.
Let’s look at a formal definition of knowledge graphs. Let E be the set of all entities in a knowledge graph, L be the set of all literals, and P be the set of relations linking an entity to another entity or an entity to a literal. Then, a knowledge graph can be defined as the subset of all possible triples of E -> P -> (E or L).
Publicly Available Knowledge Graphs
Wikidata, Freebase, and DBpedia are some massive publicly available knowledge graphs. These KGs can be queried using standard query languages such as SPARQL. Wikidata contains background information about almost any topic in the world. Here, is a page on Gal Gadot.
Knowledge Graph Question Answering Task
The KGQA task involves answering a natural language question using the information stored in a KG. The input question is first translated into a formal query language e.g., SPARQL and then this formal query is executed over the KG to fetch the answer.
The task of converting a natural question into a formal KG query is called Semantic parsing. Let’s have a look at an example –
Input: “What are all the country capitals in Africa?”
Output:
PREFIX ex: <http://example.com/exampleOntology#> SELECT ?capital ?country WHERE { ?x ex:cityname ?capital ; ex:isCapitalOf ?y . ?y ex:countryname ?country ; ex:isInContinent ex:Africa . }
Once we get the output of a semantic parser, the query can easily be executed over the KG. This makes semantic parsing the most important step in a KGQA task and a lot of research has been focused on this. Let’s have a look at some of the techniques involved in this step.
Neural Network Based Semantic Parsers
The prediction models commonly used in semantic parsing can be categorized into – classification, ranking, and translation based models. Let’s have a look at each of these methods in detail.
Classification Based KGQA Models
A semantic parser should be able to generate a target formal query of any arbitrary length. But we will look into these complex queries in detail later. A simpler task than this is when we can assume a fixed simple structure of the output query.
“Gal Gadot was born in Israel” -> <ex: Gal Gadot, ex: bornIn, ex: Israel>
Simple queries comprise one subject entity (Gal Gadot), one relation (born in), and one object entity (Israel). Classification based models tend to work well for such simple queries.
This simple query prediction task can be broken down into two sub-tasks –
- Relation prediction
- Entity Prediction
Relation Prediction
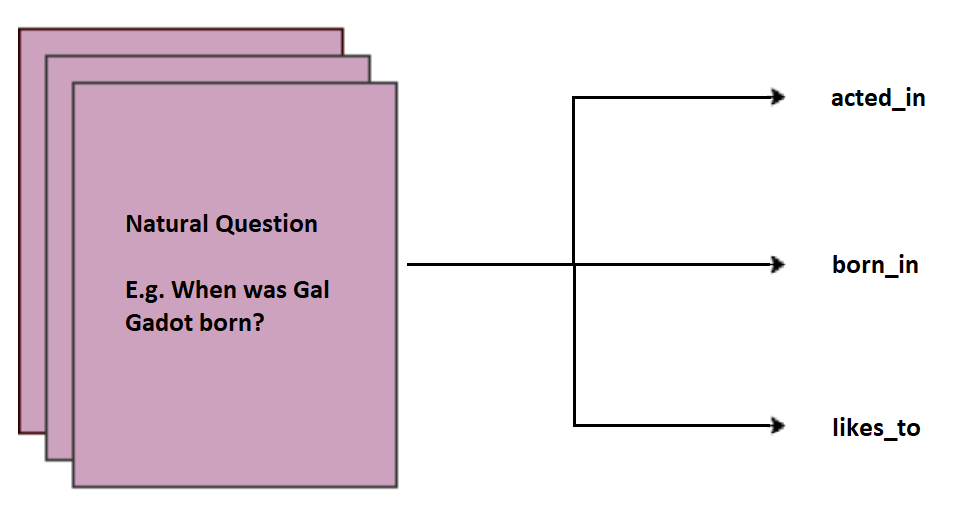
Given a natural question q, relation classification involves predicting one of the n relations of a given KG. This can be treated as a standard text sequence classification problem where the natural question q is the input and one of the n relations is the output label. The input natural question is encoded into a fixed-length vector. The encoder network can be any neural architecture (RNN, CNN, transformer, etc.). The encoder output is fed into a linear layer with dimensions N x d, where N is the number of relations in the KG and d is the size of the encoded vector. The label probabilities can be computed with a standard softmax.
Entity Prediction
We can employ the same method as above and have two similar models for relation and entity prediction. But, large KGs such as freebase contain a huge amount of entities. While the number of relations in a KG might be in thousands the number of entities can be in millions and training a classifier for millions of output labels is not feasible.
Therefore, a common two-step technique is employed for entity prediction –
- An entity span detector is employed to detect the entity form a natural question text.
“Where was Gal Gadot born?” -> “Gal Gadot”
- Then, a simple text-based retrieval method is used to find a suitable candidate(s) from the KG entities for the identified entity from the question.
The entity span prediction from a natural question can be treated as a classification problem where two separate classifiers predict the start and the end token of the entity. Or it can be treated as a sequence to sequence tagging problem which predicts for every token if it belongs to the entity or not.
Ranking Based KGQA Models
The above classification based methods will not work well for complex queries. Since the set of possible queries of arbitrary length can grow exponentially. Ranking based KGQA models employ a two-step procedure to counter this. First, they employ a search based procedure to find the top few probable query candidates. Then they use a neural network-based ranking model to find the best candidate.
Probable Candidates Search Procedure
Many techniques can be employed to reduce the probable candidate space, such as –
- Using already existing entity linking tools to limit the search space to only those formal queries that contain entities and relations within a certain distance (hops) of the entities in the input question.
- Selecting formal queries that have a fixed number of relations.
- Using beam search with a scoring mechanism.
- Eliminating invalid or incorrect queries that violate the rules of the formal query language.
Ranking Probable Candidates
Given a natural query and a set of probable target query candidates, the task of ranking involves assigning a score to each of the formal queries. This can be done in a two-step procedure –
- Encoding the natural query and every candidate to a vector space. A simple bag of words can be used for the tokens in both the input questions and the formal query. Neural network models can also be used to learn embeddings for the tokens.
- Calculating the score of every candidate using a scoring mechanism. This scoring mechanism can be a simple dot product or another neural network that takes the two vectors and outputs a score.
Training Ranking Models
Training of these ranking models involves learning parameters for the two encoders and/or the score calculator. This can be done using –
- Full Supervision, where training data consists of natural questions and their corresponding formal query representations. For these datasets, a set of negative examples (a natural question and an incorrect formal query) is generated randomly for every natural question in the dataset. And the model is trained by minimizing a point-wise or pairwise ranking loss (see this).
- Weak Supervision, where training data consists of only pairs of natural questions and corresponding answers (execution results from the KG). For these datasets, a similar search procedure that was used for probable candidates (discussed earlier) is employed to find pseudo gold labels. Then these pseudo gold labels are used for model training similar to full supervision.
Translation Based KGQA Models
In these models, semantic parsing is treated as a translation problem. A sequence-to-sequence model is learned to translate a natural question into a formal query similar to language (machine) translation models.
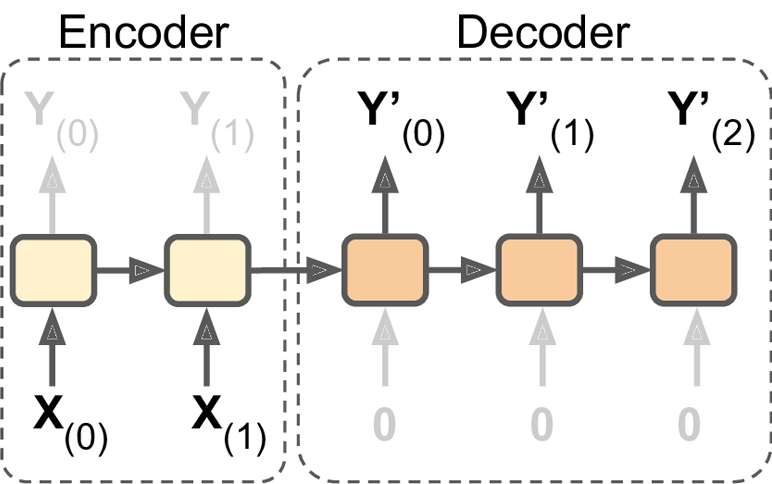
Neural sequence to sequence models are commonly used for this. A typical neural seq-to-seq model consists of –
- Encoder – It encodes the input sequence to create context-dependent representations.
- Decoder – It generates the output sequence one token at a time conditioning on the previously generated tokens and the input sequence.
RNNs, CNNs, and transformers are some of the popular encoder-decoder systems.
Constrained Decoding
A simple decoder does not leverage the strict nature of the KG queries. The output sequence that needs to be generated follows strict grammatical rules such that when executed over a KG return valid results. These rules can be leveraged during both training and inference to get better results. For example, in the case of parsing simple questions (entity -> relation -> entity), the decoder can be constrained to generate only entities in the first step, only relations as the second token, followed by only an entity in the third step.
Further Reading
I am very excited to see knowledge graphs gain so much traction of late. If you are interested in digging further, I highly recommend these resources –
- Chakraborty et al., 2019 – A comprehensive study on knowledge graph question answering.
- Knowledge Graphs in Natural Language Processing @ ACL 2019
I hope you enjoyed the post. Given my recent interest, you can expect many more posts on knowledge graphs. Please stay tuned for more :-).

Thanks for this wonderful posting about Knowledge graph. Knowledge Graph is the key criteria for any industry.
LikeLike
Yashu, thank you very much for sharing your knowledge with this comprehensive dossier!
LikeLike