Transfer Learning in natural language processing is an area that had not been explored with great success. But, last month (May 2018), Jeremy Howard and Sebastian Ruder came up with the paper – Universal Language Model Fine-tuning for Text Classification which explores the benefits of using a pre-trained model on text classification. It proposes ULMFiT, a transfer learning method that can be applied to any task in NLP. This method outperforms the state-of-the-art on six text classification tasks.
In this blog post, I will explain the step-by-step working of the method proposed in this paper.
ULMFiT uses a regular LSTM (without any attention short-cut connection or any other complex addition) which is the state-of-the-art language model architecture (AWD-LSTM, Merity et al., 2017a). The LSTM network has 3 layers. (Edit: You can find my blog post giving a walkthrough of the AWD-LSTM paper here – What makes the AWD-LSTM great?) This single architecture is used throughout – for pre-training as well as for fine-tuning.
There are three stages in ULMFiT –
- General domain language model pre-training
- Target task language model fine-tuning
- Target task classifier fine-tuning
We will discuss each of these stages in detail.
General Domain Language Model Pre-Training
This step is analogous to the ImageNet pre-training in computer vision. Since language modeling (next word prediction) can capture general properties of a language it serves as an ideal source task for pre-training a network. The network is pre-trained on Wikitext-103 (Merity et al., 2017b). It consists of 28,595 preprocessed English Wikipedia articles and 103 million words.
Target Task Language Model Fine-Tuning
Instead of directly using the Wikipedia pre-trained model and fine-tuning it for the classification task, there is an intermediate step involved. In this step, the language model is fine-tuned on data from the target task (on which classification will be performed). This step improves the classification model (discussed in the third step) on small datasets. The paper proposes the following methods to achieve this step-
Slanted Triangular Learning Rates
The target text (here, the text on which classification needs to be done) has a different distribution than the one on which our language model has been pre-trained. The goal for fine-tuning in this stage is to make the model parameters adapt to the task-specific text features. For this, the authors propose slanted triangular learning rates (STLR) in which, the learning rate first increases linearly and then decays linearly. STLR is a modification of the triangular learning rates (Smith 2017) with a short increase and a long decay period.
Intuition – An initial short increase in the learning rate is required because we want the model to quickly converge to a suitable region of the parameter space for the target task. This is followed by a long decay period which allows for the further refining of the parameters. Hence, using the same or an annealed (decaying) learning rate would not be suitable.
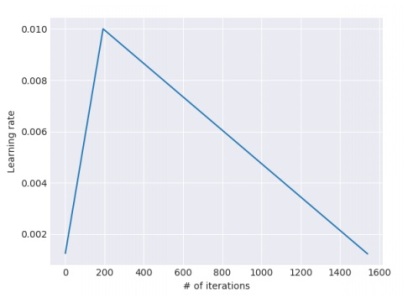
The update schedule for the STLR can be given as –

where,
- T is the number of training iterations (where one training iteration is equal to the number of epochs times the number of updates per epoch).
- cut_frac is the fraction of iterations we increase the LR.
- cut is the iteration when we switch from increasing to decreasing the LR.
- for t < cut, p is the number of iterations the LR has increased upon the total number of increasing iterations and, for t >= cut, p is the total number of iterations the LR has decreased upon the total number of decreasing iterations.
- ratio specifies how much smaller the lowest LR is from the maximum LR, ηmax.
- ηt is the learning rate at iteration t.
- generally, cut_frac = 0.1, ratio = 32 and ηmax = 0.01
Discriminative Fine-Tuning
Jeremy first introduced discriminative fine tuning as differential learning rates in his course – fast.ai, Part1 2018, Lecture 1. The basic principle behind this is that different layers in a model capture different types of information and hence require different learning rate. The initial layers capture the most general form of information. Here is an awesome visualization toolkit on this.
Similarly, in a language modeling task, the first few layers would have the most general information of the language and would require the least amount of fine-tuning (change in their weights). Subsequently, as we move towards the last layer the amount of required fine-tuning would increase.
Therefore, instead of using the same learning rate in the entire model, the paper proposes to use different learning rates for each layer. It first chooses the learning rate of the last layer by fine-tuning only the last layer and uses the following formula for the lower layers –
ηl-1 = ηl / 2.6, where ηl is the learning rate of the l-th layer.
Target Task Classifier Fine-Tuning
The final stage in ULMFiT involves training the model with two additional linear blocks. ReLU activation is used for the intermediate layer and softmax for the final linear layer. Each block uses batch normalization and dropout.
Concat Pooling
The first linear layer takes as input the pooled last hidden layer states. The signal in a text classification task is often contained in a few words, which may occur anywhere in the document. Hence, information may get lost if we only consider the last hidden state of the model. Therefore, the last hidden state of the model is concatenated with the max-pooled and the mean-pooled representations of the hidden states over as many time step as fit in the GPU memory.
Gradual Unfreezing
The target classifier fine-tuning is very sensitive and an aggressive fine-tuning may lead to nullifying the benefits of language model pre-training. Therefore, the authors propose gradual unfreezing for fine-tuning the classifier.
- The last LSTM layer is first unfrozen and the model is fine-tuned for one epoch.
- Then the next lower frozen layer is unfrozen.
- This process is repeated until all layers are fine-tuned to convergence.
BPTT for Text Classification (BPT3C)
Similar to backpropagation through time for language modeling, BPTT for text classification is introduced. The document is divided into fixed-length chunks. At the beginning of each chunk, the model is initialized with the final state of the previous chunk. Gradients are back propagated to the batches whose hidden state contributed to the final prediction. In practice, variable length backpropagation sequences are used (Merity et al., 2017a).
Bidirectional language model
Both, a forward and backward language model are pre-trained. The classifier is then fine-tuned for both the language models independently. The average of the two classifier predictions is taken as the final output.
Further Reading
- The research paper – Understanding the Working of Universal Language Model Fine Tuning (ULMFiT)
- Cutting Edge Deep Learning for coders – Lesson 10, Part2 2018, fast.ai
-
Introducing state of the art text classification with universal language models
- Pre-trained Wikitext 103 model and vocab
(Edit) A big thanks to Jeremy Howard for the shout-out 😊

[…] Understanding the working of Universal Language Model Finetuning […]
LikeLike
[…] If you are interested in transfer learning, you should check out the recent work of Jeremy Howard and Sebastian Ruder on ULMFiT (here and here). […]
LikeLike
[…] by the idea of using language models, popularized this year by Fast.ai’s UMLFit (see also “Understanding UMLFit”). We have then seen other (and improved) approaches like Allen’s ELMO, Open AI’s […]
LikeLike
Can you please explain more about concat pooling in the final classification layer? If we get multiple hidden states each from bptt length of input sentence, how are we going to get a final number between 0 and 1? Any paper explaining this approach would be great. Thanks in advance.
LikeLike
Let’s say we got h_1, h_2, h_3 ….. h_n hidden states from the last layer. These hidden states are combined as follows –
concat(max(h_1, h_2, …. h_n), mean(h_1, h_2, …. h_n), h_n)
Let’s call this vector h_final. h_final is now fed to a linear layer. The output of this linear layer (say, f1) is fed to another linear layer whose output dimension is 1 (in case of binary classification) and this gives the output (say, f2). f2 is a single real number. This f2 is fed to a sigmoid layer to get a number between 0 and 1.
LikeLike
Can you explain what embeddings are used
LikeLike
There are no pre-trained embeddings used. They are randomly initialized and learned during the language model pre-training step.
LikeLike
Thank you..is ULMFIT can be used to classify 4 labels
LikeLike
Yes, it can be used to classify any number of labels.
LikeLike
[…] ULMFiT […]
LikeLike