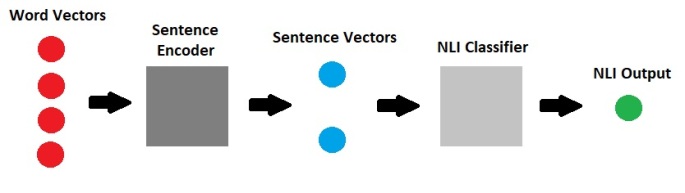
Universal Embeddings of text data have been widely used in natural language processing. It involves encoding words or sentences into fixed length numeric vectors which are pre-trained on a large text corpus and can be used to improve the performance of other NLP tasks (like classification, translation). While word embeddings have been massively popular and … Continue reading A Walkthrough of InferSent – Supervised Learning of Sentence Embeddings